Spark 配置
Apache Spark 是一个开源集群运算框架,作用类似于 Hadoop 的 MapReduce 。但是相对于 MapReduce 来说它的速度要快得多。
环境介绍
软件版本如下:
| Program | Version | URL |
|---|---|---|
| System | CentOS-7-x86_64-Minimal-1810 | TUNA Mirrors |
| JAVA | jdk-8u211-linux-x64.tar.gz | Oracle |
| Hadoop | hadoop-2.6.0.tar.gz | Apache Archive |
| Spark | spark-2.0.0-bin-hadoop2.6.gz | Apache Archive |
| ZooKeeper | zookeeper-3.4.5.tar.gz | Apache Archive |
目标
- 完成 Standalone 集群搭建
- 在 YARN 上运行 Spark
- 在 Mesos 上运行 Spark
基础环境配置
参考 Hadoop HA 搭建 目前已完成 Hadoop/ZooKeeper 环境搭建
下载解压
1 | curl -O http://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0-bin-hadoop2.6.tgz |
Standalone Mode
使用这种模式搭建,不需要借助其他外部工具(高可用性需要 ZooKeeper)
手动启动集群
先搭建一个最简单的
| HostName | Mode | IP |
|---|---|---|
| master | Master | 192.168.66.128 |
| slave1 | Worker | 192.168.66.129 |
| slave2 | Worker | 192.168.66.130 |
不需要修改任何配置,直接启动即可。
1 | master |
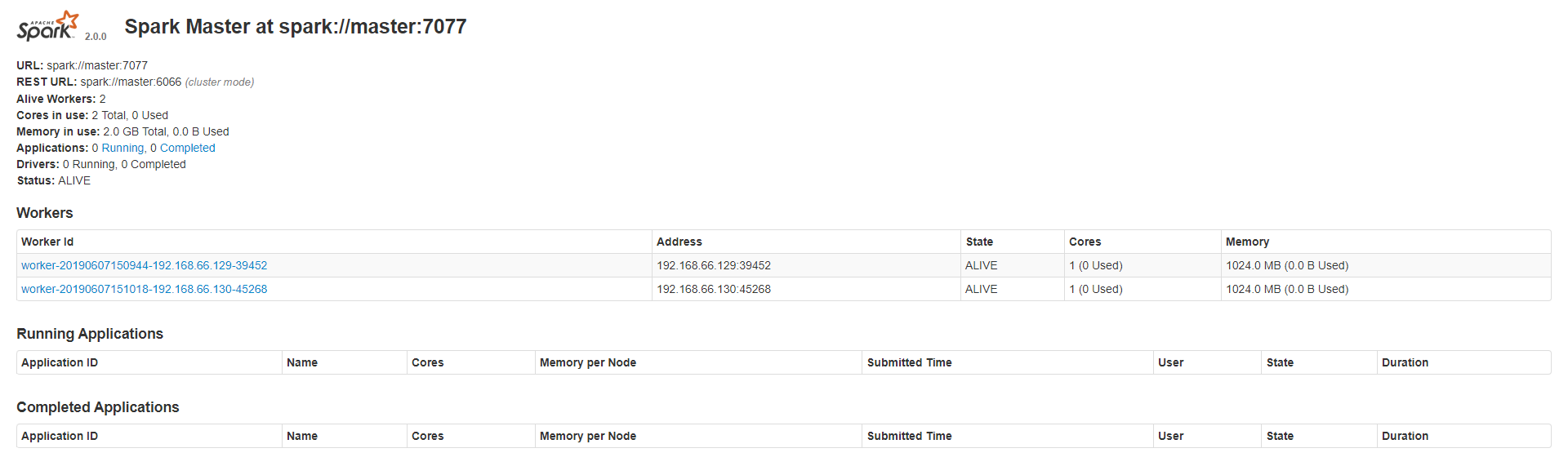
用浏览器打开的 Web UI 看看 http://master:8080/
其中的 URL 是让其他的 Workers 连接到 master 的重要参数

将程序传到另外两台机子上
1 | scp -r /usr/local/src/spark slave1:/usr/local/src/ |
接下来在另外两台机子上启动 workers 并连接到 master
1 | 两台机子都要运行 |
如图出现了两个 Worker 且 State 处于 ALIVE 搭建完毕
脚本启动集群
首先将之前启动的服务都手动关掉
1 | master |
1 | 两个 slave 都需要关闭 |
将默认的配置文件改名为正式使用
1 | cd /usr/local/src/spark/conf/ |
修改 slaves 文件删掉里面的所有内容写入以下内容
1 | slave1 |
修改 spark-env.sh 文件指定 master,写入以下内容
1 | SPARK_MASTER_HOST=master |
如果不写
JAVA_HOME的话,在启动slave的时候会报JAVA_HOME is not set估计是因为我的JAVA_HOME设置的仅对root生效的原因吧
将配置文件同步给另外两台机子
1 | scp -r /usr/local/src/spark/conf/ slave1:/usr/local/src/spark/ |
在 master 上面启动 master 和 slaves
1 | cd /usr/local/src/spark/sbin/ |
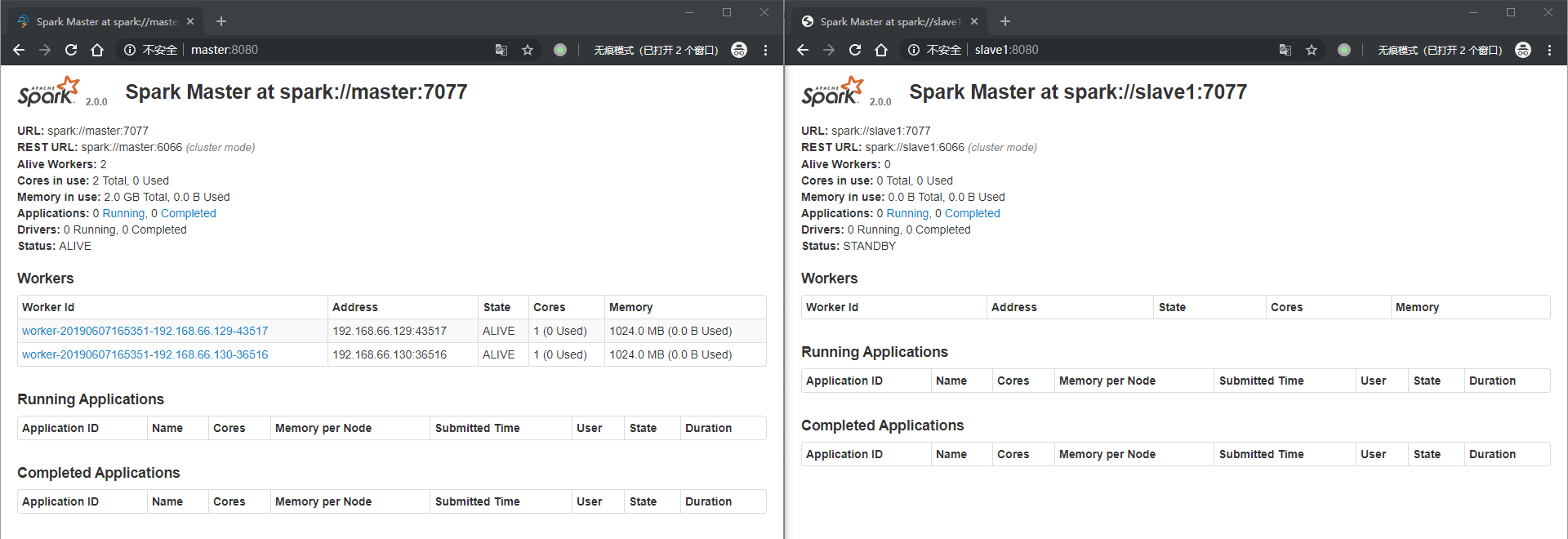
启动成功后浏览器打开 http://master:8080/ 看看,应该和上面的图片是一样的
下面的命令可以关闭
1 | ./stop-master.sh |
高可用
编辑配置文件
1 | vi /usr/local/src/spark/conf/spark-env.sh |
在配置文件中新增以下内容
1 | SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/sparkha" |
注意如果你之前添加了
SPARK_MASTER_HOST=master要删掉,因为master的任命被ZooKeeper接管了这个配置没用了
将配置同步到另外两台机器上
1 | scp -r /usr/local/src/spark/conf/ slave1:/usr/local/src/spark/ |
启动 ZooKeeper,如果你还没有配置可以参考这篇文章Hadoop HA 配置 - ZooKeeper 配置
1 | 每台机子都要启动 |
在 mastrt 上启动 master 和 slaves
1 | ./start-master.sh |
在 slave1 上启动 备用 master
1 | ./start-master.sh |
参考
博客园@Mr.心弦 - Kafka【第一篇】Kafka集群搭建