接上文,我们已经完成了 Hadoop 伪分布部署 接下来就可以配置 Flume 了。
Flume 介绍 Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力。
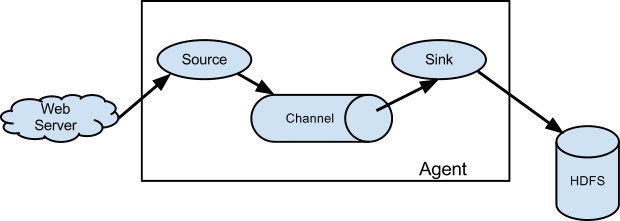
Flume Agent (代理) 主要由以下三部分组成
Source : 从外部接收 Source 所识别格式的数据,并向 Flume 发送 事件(Avent) 。当 Flume 接收到事件后,会将它储存到一个或多个 ChannelChannel : 一个被动的储存器,用于保存事件,直到被 sink 消耗为止sink : 从 Channel 中移除事件并将其放入 外部储存库 (例如:HDFS),或将其转发到下一个 Flume Agent 的 Flume Source。
Flume 中的 Source、 Channel 和 sink 之间暂存的事件是异步运行的
这里我主要使用 Flume 实现以下功能:
监听5555网络端口
将从网络端口接收到的数据落地到hdfs以下目录 /raw_data/receive/
文件名称格式以 [YYYYMMDD]_ 为前缀
每接收 10M 数据落地一个文件,当接收数据不足 10M 时,每 15分钟 落地一个文件。
准备工作 下载解压 Flume 我使用的是 Flume 1.6.0
1 2 3 curl -O http://192.168.66.1/apache-flume-1.6.0-bin.tar.gz # 从本地下载 curl -O http://archive.apache.org/dist/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz # 需要连接到公网 tar -xf apache-flume-1.6.0-bin.tar.gz # 解压
环境变量 在文件末尾添加以下内容
1 2 export FLUME_HOME=/root/apache-flume-1.6.0-bin export PATH=$PATH:$FLUME_HOME/bin
让系统更新配置文件
测试配置是否成功
输出以下信息说明配置成功
1 2 3 4 5 Flume 1.6.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080 Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015 From source with checksum b29e416802ce9ece3269d34233baf43f
检测依赖 输出以下信息说明 NameNode 正常运行
1 2 3 4 33377 Jps 20854 DataNode 20998 SecondaryNameNode 20743 NameNode
看看 NameNode 的 WEB 端是否正常运行
http://192.168.66.135:50070
如果它运行异常, Flume 是无法将数据正确写入 HDFS 的
配置示例 Flume 编辑示例配置 1 vi /root/apache-flume-1.6.0-bin/conf/example.conf
写入以下信息,该示例配置来自于 Flume docs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # Flume 示例配置,监听 44444 端口,并将来自该端口的信息存储在内存中,最后把信息打印在终端 # 为该 Agent 的组件设置名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 设置 Sources 的属性,侦听网络端口并将每行文本转换为 Event # http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#netcat-source a1.sources.r1.type = netcat a1.sources.r1.bind = master a1.sources.r1.port = 44444 # 设置 Sinks 的属性,在日志中以 INFO 级别记录所有 Event # http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#logger-sink a1.sinks.k1.type = logger # 设置 Channels 的属性,将 Event 储存在内存中 # http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#memory-channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 将 Sources 和 Sinks 绑定到 Channels a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
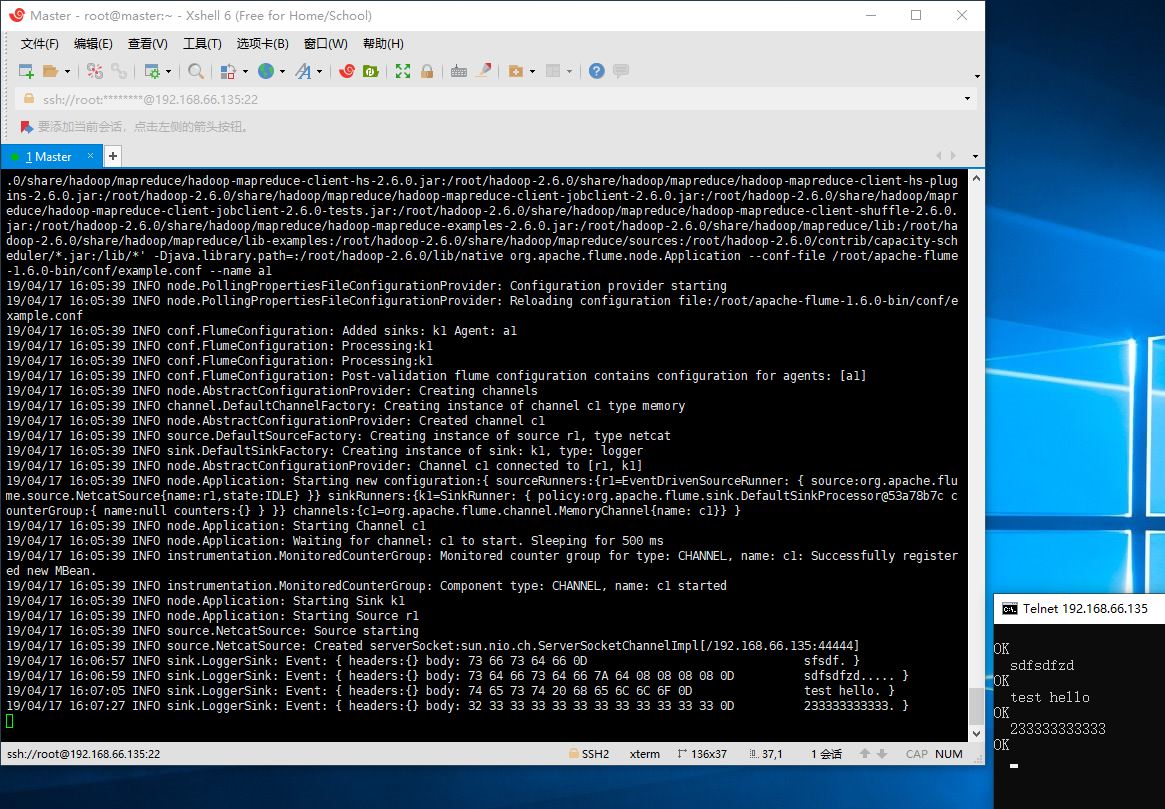
运行示例配置的 Flume 1 2 start-dfs.sh # 启动 HDFS flume-ng agent --conf-file /root/apache-flume-1.6.0-bin/conf/example.conf --name a1
发送测试数据 使用真机的 telnet 连接到 Flume 服务器,发送任意字符串查看终端有没有显示相关信息。
1 telnet 192.168.66.135 44444
‘telnet’ 不是内部或外部命令,也不是可运行的程序或批处理文件。请到 控制面板-程序和功能-启动或关闭 Windows 功能 勾选 Telnet Client
配置 Flume 编辑配置 1 vi /root/apache-flume-1.6.0-bin/conf/flume.conf
写入以下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # Flume 完整配置,监听 5555 端口,并将来自该端口的信息存储在本地文件中,最后把信息发送到 HDFS # 为该 Agent 的组件设置名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 设置 Sources 的属性,侦听网络端口并将每行文本转换为 Event # http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#netcat-source a1.sources.r1.type = netcat a1.sources.r1.bind = master a1.sources.r1.port = 5555 # 设置 Sinks 的属性,将落地到 HDFS # http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#hdfs-sink a1.sinks.k1.type = hdfs # 设置路径 a1.sinks.k1.hdfs.path = hdfs://master:9000/raw_data/receive/ # 设置前缀 a1.sinks.k1.hdfs.filePrefix = [%Y%m%d]_ # 落地文件大小单位为 bytes a1.sinks.k1.hdfs.rollSize = 10485760 # 无视基于事件块的落地配置 a1.sinks.k1.hdfs.rollCount = 0 # 超时落地文件 a1.sinks.k1.hdfs.rollInterval = 900 # 设置使用本地时区,如果不设置的话会报错 a1.sinks.k1.hdfs.useLocalTimeStamp = true # 设置 Channels 的属性,将 Event 储存在文件中 # http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#file-channel a1.channels.c1.type = file # 存放 event 在那个 data 文件 logFileID ,的什么位置 offset 等信息,相当于索引 a1.channels.c1.checkpointDir = /root/flume/checkpoint # 主数据文件 a1.channels.c1.dataDirs = /root/flume/data # 将 Sources 和 Sinks 绑定到 Channels a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
运行 1 flume-ng agent --conf-file /root/apache-flume-1.6.0-bin/conf/flume.conf --name a1
输出类似下列信息说明配置成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 19/04/17 16:49:14 INFO instrumentation.MonitoredCounterGroup: Component type: SINK, name: k1 started 19/04/17 16:49:29 INFO hdfs.HDFSSequenceFile: writeFormat = Writable, UseRawLocalFileSystem = false 19/04/17 16:49:29 INFO hdfs.BucketWriter: Creating hdfs://master:9000/raw_data/receive//[20190417]_.1555490969042.tmp 19/04/17 16:49:43 INFO file.EventQueueBackingStoreFile: Start checkpoint for /root/flume/checkpoint/checkpoint, elements to sync = 4 19/04/17 16:49:43 INFO file.EventQueueBackingStoreFile: Updating checkpoint metadata: logWriteOrderID: 1555490953596, queueSize: 0, queueHead: 2 19/04/17 16:49:43 INFO file.Log: Updated checkpoint for file: /root/flume/data/log-9 position: 1654 logWriteOrderID: 1555490953596 19/04/17 16:49:43 INFO file.LogFile: Closing RandomReader /root/flume/data/log-7 19/04/17 16:50:13 INFO file.EventQueueBackingStoreFile: Start checkpoint for /root/flume/checkpoint/checkpoint, elements to sync = 1 19/04/17 16:50:13 INFO file.EventQueueBackingStoreFile: Updating checkpoint metadata: logWriteOrderID: 1555490953601, queueSize: 0, queueHead: 2 19/04/17 16:50:13 INFO file.Log: Updated checkpoint for file: /root/flume/data/log-9 position: 1840 logWriteOrderID: 1555490953601 19/04/17 16:50:13 INFO file.Log: Removing old file: /root/flume/data/log-7 19/04/17 16:50:13 INFO file.Log: Removing old file: /root/flume/data/log-7.meta 19/04/17 17:04:30 INFO hdfs.BucketWriter: Closing hdfs://master:9000/raw_data/receive//[20190417]_.1555490969042.tmp 19/04/17 17:04:30 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/raw_data/receive/[20190417]_.1555490969042.tmp to hdfs://master:9000/raw_data/receive/[20190417]_.1555490969042 19/04/17 17:04:30 INFO hdfs.HDFSEventSink: Writer callback called.
排错 之前遇到了一个问题
1 There are 0 datanode(s) running and no node(s) are excluded in this operation
这个问题是因为多次格式化 HDFS 导致了 ID 错乱,所以无法正确的写入文件。删除一下之前的文件然后重新格式化就好了。
1 2 3 4 5 stop-all.sh # 停止所有服务 rm -rf /tmp/* rm -rf /root/hadoop-2.6.0/tmp hdfs namenode -format start-dfs.sh
接下来再启动 flume 就行了
其他 sources 由于信息来源多种多样,配置方法都大相径庭,参考官方的文档配置即可。
Avro Source
Flume到Flume
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#avro-source
HTTP Source
通过POST和GET接收数据
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html#http-source
其他 大数据系列文章 请看 这里
参考 Flume 1.6.0 User Guide
StackOverFlow@prayagupd - There are 0 datanode(s) running and no node(s) are excluded in this operation
开源中国@海岸线的曙光 - Flume日志收集之Logger和HDFS数据传输方式
博客园@项羽齐 - 大数据3-Flume收集数据+落地HDFS
简书@Woople - Flume HDFS Sink常用配置深度解读
lxw的大数据田地 - Flume中的HDFS Sink配置参数说明