Hadoop 伪分布部署
单机安装 Hadoop 还是比较简单,这里就使用 VMware 模拟部署一下。年轻人的一次大数据之旅??
新建虚拟机
下载镜像:https://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1810.iso
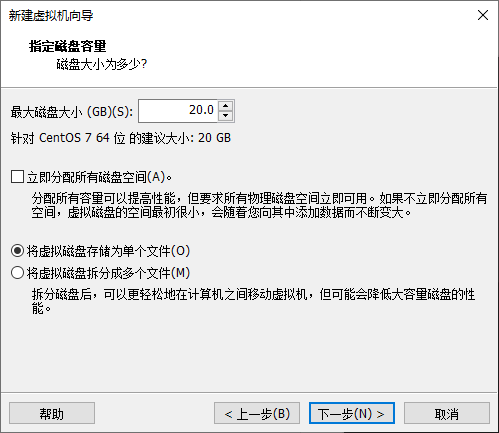
内存和硬盘大小请根据情况而定。其次,我一般习惯在创建完虚拟机后,进入虚拟机设置将打印机移除再启动。
按方向键将焦点移动至上方 Install CentOS 7 并回车
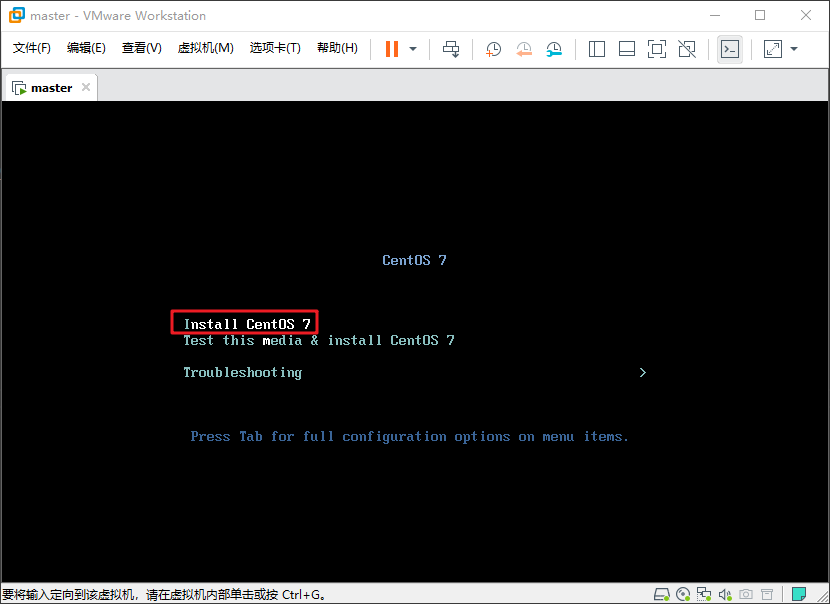
直接点 Continue 使用英语的话遇到问题方便在网上找解决方法
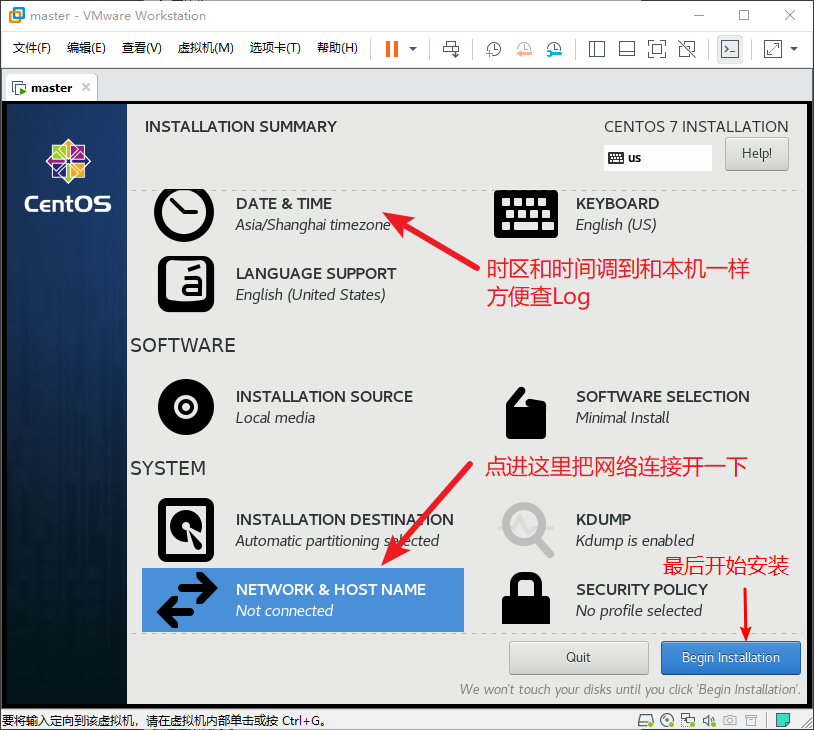
首先为了查 Log 方便,进入 DATE & TIME 把时区和时间调到和本机一样。
点进 NETWORK & HOST NAME 把网络连接打开
最后点击开始安装
安装的时候可以设置 Root 密码,安装完了直接点 Reboot 重启就完事儿了
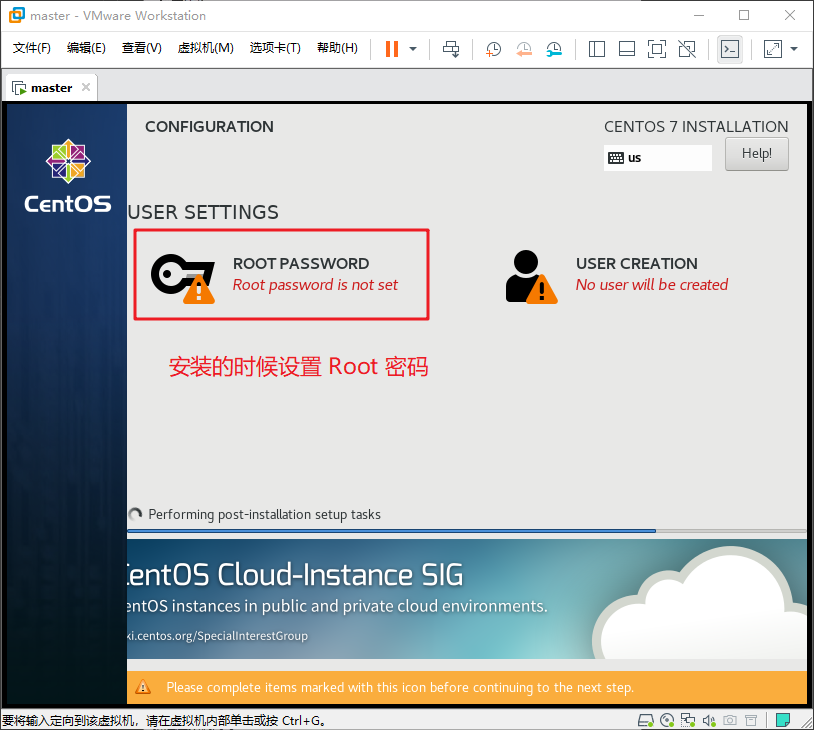
等待它出现
1 | CentOS Linux 7 (Core) |
的时候就说明安装完毕了,然后我们输入 root 和你刚刚设置的密码。登陆系统后输入 ip add 查询一下本机IP。
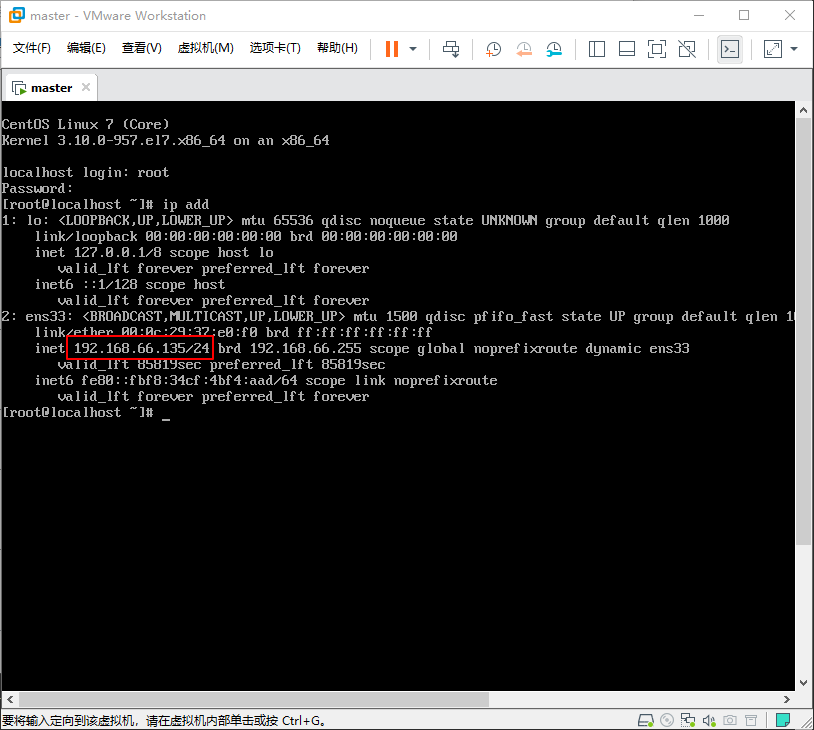
有了本机 IP 就可以换用 Xshell, putty, secureCRT 之类的软件使用 SSH 连接了。可以快乐的复制粘贴了,这里我以 Xshell 为例。
Xshell 的 复制 快捷键为
Ctrl+Insert, 粘贴 快捷键为Shift+Insert(在标准键盘中 Insert 在 Delete 的上面)
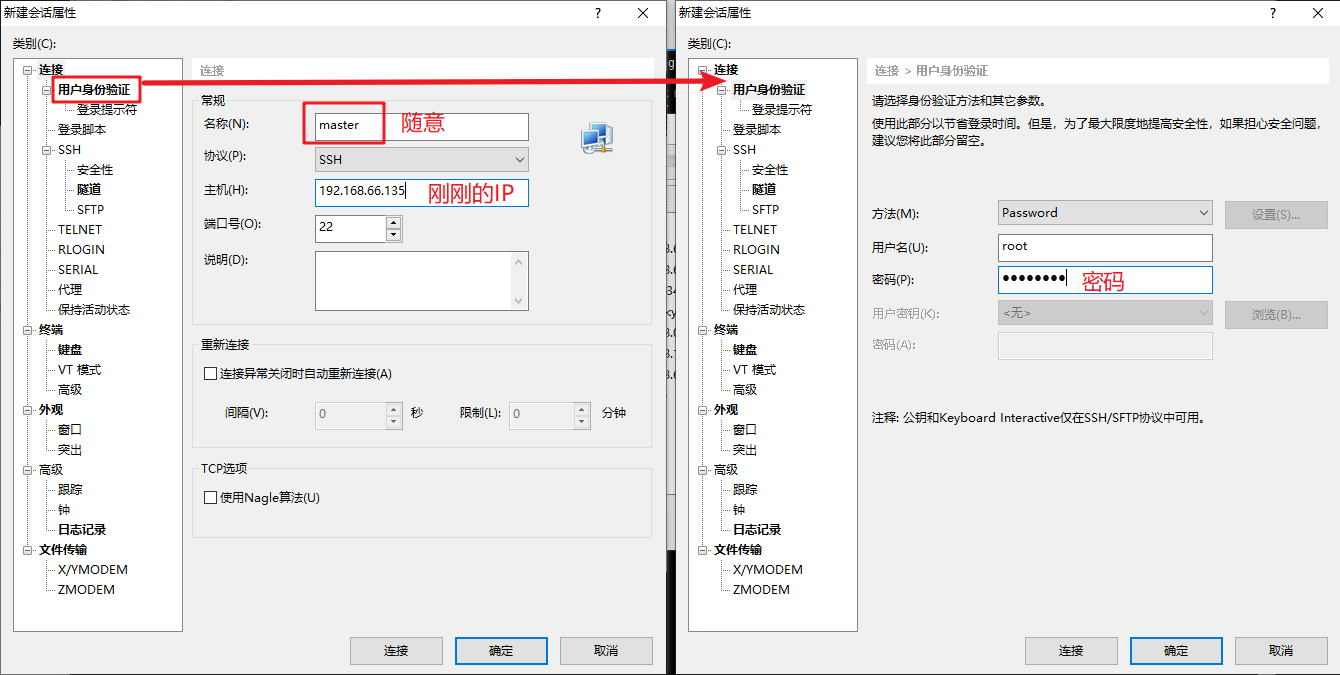
新建会话填写 名称 和 IP ,然后点击侧栏的 用户身份验证 填入 用户名 和 密码
再然后点击侧栏 SSH 里面的 隧道 ,将下面的 转发X11连接到 关闭。
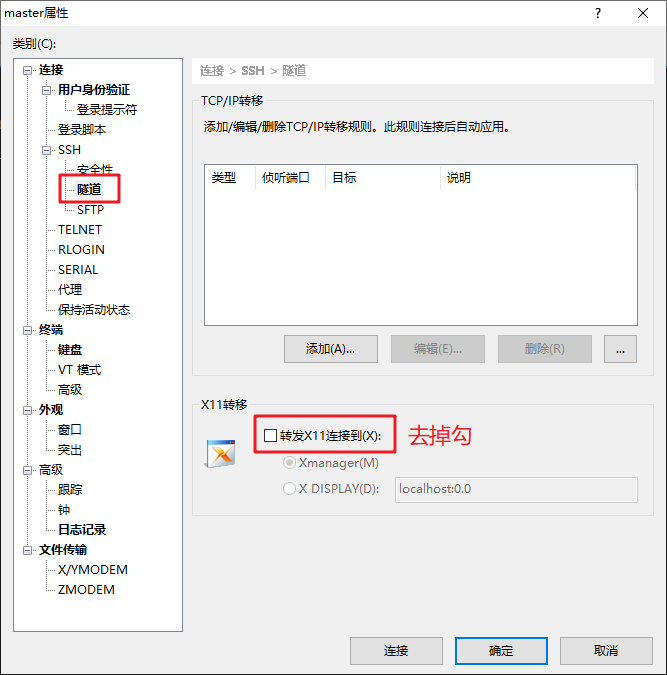
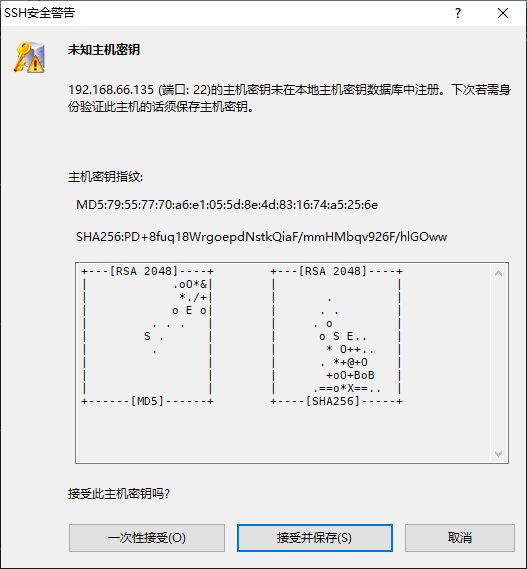
点击确定,连接后提示 未知主机密钥 选择 接收并保存 即可
服务器基本环境配置
关闭防火墙
1 | systemctl stop firewalld # 关闭防火墙 |
当它输出以下提示时意味着这一步你已经完成了
1 | not running |
关闭 Selinux
想了解有关它的更多信息请自行搜索
首先打开配置文件
1 | vi /etc/selinux/config |
修改字段如下
1 | This file controls the state of SELinux on the system. |
保存并退出 vi 的方法是 按 esc 后输入 :wq 。有关 vi 的更多操作请自行搜索
随后输入以下指令重启以生效
修改 hostname
1 | hostnamectl set-hostname master # 修改 hostsname 为 master |
由于 HDFS 钟爱于使用 localhosts 所以要将 hosts 里面有关的信息都注释掉,修改后 hosts 文件如下
1 | # 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 |
1 | reboot # 重启生效 |
安装 Java
下载 https://www.oracle.com/cn/java/technologies/javase/javase8u211-later-archive-downloads.html
我选择了 Linux x64 rpm 安装包
在下载目录的空白处按住 Shift 点击鼠标右键,然后点击 在此处打开 PowerShell 窗口 召唤出来 PowerShell ,因为本机有 Python 环境,所以就使用 python -m http.server 80 启动一个简易的 http服务 。然后用浏览器打开 服务器IP的默认网关 一般情况下与 服务器IP 的差别只有 最后一位为1 。这里我就选择打开 192.168.66.1。并复制 Java JDK 链接。
别忘了关闭 Windows 防火墙,python2(CentOS7 自带) 的http服务命令是
python -m SimpleHTTPServer 80
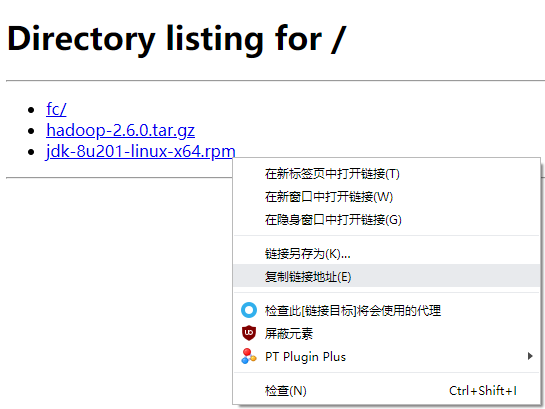
在 CenOS 下输入以下命令下载并安装
1 | curl -O http://192.168.66.1/jdk-8u201-linux-x64.rpm #这里应该替换为你刚刚复制的链接 |
当你看到控制台输出类似信息说明你已安装成功
1 | [root@master ~] curl -O http://192.168.66.1/jdk-8u201-linux-x64.rpm |
测试一下
1 | java -version |
输出以下信息说明安装成功
1 | java version "1.8.0_201" |
安装 Hadoop
下载 https://archive.apache.org/dist/hadoop/core/hadoop-2.6.0/hadoop-2.6.0.tar.gz
还是使用老办法将文件传进 CentOS
1 | curl -O http://192.168.66.1/hadoop-2.6.0.tar.gz # 这里应该改成你复制的链接 |
接下来我们要为 JAVA 和 Hadoop 配置环境变量,首先打开配置文件 vi /etc/profile 按一下大写 G 转跳到文本底部,添加内容后文本底部如下。
1 | for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do |
输入以下内容让系统更新配置文件
1 | source /etc/profile |
输入以下内容检测配置是否正常
1 | hadoop version |
当返回如下信息时说明你的配置已经成功了
1 | Hadoop 2.6.0 |
配置 SSH 实现免密登陆
1 | ssh-keygen -t rsa |
然后一直回车,输出信息如下即可
1 | [root@master hadoop-2.6.0] ssh-keygen -t rsa |
生成 authorized_keys
1 | cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys |
使用以下命令测试能否实现免密码登陆
1 | ssh master |
如果你只输入了 Yes 就登陆成功了,说明这一步你配置成功了。然后输入 exit 退出后进行下一步配置。
配置 Hadoop
开始配置之前我建议你创建一次快照
进入 Hadoop 目录
1 | cd /root/hadoop-2.6.0/etc/hadoop/ |
core-site.xml
1 | vi core-site.xml |
在 <configuration> 和 </configuration> 之间添加以下内容
1 | <!-- 指定 HADOOP 所使用的文件系统 schema(URI),HDFS 的老大(NameNode)的地址 --> |
hdfs-site.xml
vi hdfs-site.xml
在 <configuration> 和 </configuration> 之间添加以下内容
1 | <!-- 指定 HDFS 副本的数量 --> |
mapred-site.xml
1 | cp mapred-site.xml.template mapred-site.xml |
在 <configuration> 和 </configuration> 之间添加以下内容
1 | <!-- 指定 mr 运行在 yarn 上 --> |
yarn-site.xml
vi yarn-site.xml
1 | <!-- 指定 YARN 的老大(ResourceManager)的地址 --> |
hadoop-env.sh
1 | vi hadoop-env.sh |
在文档最下面新增一行
1 | export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64 |
运行 Hadoop
1 | hdfs namenode -format # 格式化 HDFS |
停止 Hadoop
调整了配置后,一定要先停止再启动
1 | stop-dfs.sh # 停止 HDFS |
其他 大数据系列文章 请看 这里
测试
http://192.168.66.135:50070 # NameNode
http://192.168.66.135:19888 # 历史服务器
http://192.168.66.135:8088 # 资源管理器
参考
Hadoop: The Definitive Guide@Tom White