机器学习西瓜书 学习笔记
记录自己的学习,以及为期末考试准备一份复习资料,不过复习的主要目的也不是为了那一份资料,而是复习的过程吧。我个人一直都对机器学习的「无中生有」比较感兴趣,正是这样的兴趣推动了我选择了这个专业方向。目前看来,大量的数学公式推导确实让我非常吃力,但是也算是满足了自己一窥端倪的好奇心。
写在最前面
本系列文章都会遵守 中文文案排版指北,愿各位看官和我都能够跟自己爱的人结婚😀。
「有研究显示,打字的时候不喜欢在中文和英文之间加空格的人,感情路都走得很辛苦,有七成的比例会在 34 岁的时候跟自己不爱的人结婚,而其余三成的人最后只能把遗产留给自己的猫。毕竟爱情跟书写都需要适时地留白。
与大家共勉之。」——vinta/paranoid-auto-spacing
绪论
基本术语
假设收集了一批关于西瓜的数据
| 色泽 | 根蒂 | 敲声 |
|---|---|---|
| 青绿 | 蜷缩 | 混响 |
| 乌黑 | 稍蜷 | 沉闷 |
| 浅白 | 硬挺 | 清脆 |
数据集:上面这一组数据的集合。
样本:每一条(行)记录是关于一个时间或对象(这里是西瓜)的描述。
属性/特征:反映时间或对象在某方面的表现或性质,例如「色泽」、「根蒂」、「敲声」。
属性值:属性上的取值,例如「青绿」、「乌黑」。
属性空间/样本空间:属性张成的空间,比如把“色泽” “根蒂” “敲声”作为三个坐标轴,则他们张成一个用于描述西瓜的三维空间。这个空间就是属性空间。
特征向量:把每个属性作为一个坐标轴,则它们能够组成一个多维空间,那么每一个实例都能够在空间中找到自己的坐标位置。因为每个点都对应一个坐标向量,因此一个实例也称特征向量。
维数:因为每个属性都作为一个坐标轴,而又因为有多少个坐标轴我们就将这个空间叫做几维空间,所以维数也就是样本有多少个属性。
学习/训练:从数据中学的模型的过程,学习的过程是通过执行某个学习算法来完成的。
训练数据:训练过程中使用的数据。
训练样本:训练过程中每个样本。
训练集:训练样本组成的集合。
假设:学得模型对应关于数据的某种潜在的规律。
标记:样本的好或坏,一般都是布尔值。
样例:拥有标记值的样本。
标记空间/输出空间:所有标记的集合。
分类任务:预测的结果是离散值的任务。
回归任务:预测的是连续值,比如西瓜的成熟度 0.95、0.37。
二分类任务:只要涉及的类别只有两个,通常一个为正类,另一个为反类。
多分类任务:涉及多个类别,也即是大于两个吧。
测试:使用学得的模型进行预测。
测试样本:被预测的样本。
聚类:将训练集中的西瓜分成若干组,例如高工资、低工资。
簇:被聚类成分成的组,每一组就是一个簇。
监督学习:有标记信息,分类任务和回归任务。
半监督学习:监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。
无监督学习:无标记信息,聚类任务。
泛化能力:学的模型适用于新样本的能力。具有强泛化能力的模型能很好地适应于整个样本空间。
独立同分布:可以先假设样本空间都服从一个未知的分布,我们获得的每个样本都是独立的从这个分布上采样获得的,即独立同分布。一般而言,训练样本越多,我们获得关于该分布的信息越多,就越有可能通过学习获得具有强泛化能力的模型。
术语例题
| 编号 | 姓名 | 年收入 | 性别 | 职业 | 好顾客 |
|---|---|---|---|---|---|
| 1 | 张三 | 高 | 男 | 程序员 | 是 |
| 2 | 李四 | 高 | 男 | 企业家 | 是 |
| 3 | 王五 | 中 | 男 | 公务员 | 否 |
| 4 | 周六 | 低 | 女 | 学生 | 否 |
| 5 | 钱七 | 中 | 女 | 教师 | 否 |
- 上表中样本是?
- 一共有多少样本?
- 样本的属性都是?
- 样本标记是?
- 用户「周六」属性值和标记值是?
假设空间
科学推理的两个基本手段:演绎、归纳。
演绎:从一般到特殊的特化,即从基础原理推演出具体状况,例如数学公式就是从一些常识和推理逻辑,推导出了相洽的定理。
归纳:从特殊到一般的泛化过程,就是从具体的事实归结出一般性规律。机器学习也就是用的这种推理方法。
广义的归纳学习:从样例中学习。
狭义的归纳学习:从训练数据中学得概念。
狭义的归纳学习,有时候也成为概念学习。概念学习中最基础的就是布尔概念学习,也就是对「是」「不是」这样的目标概念的学习。
假设的确定
我们可以把学习的过程看做一个在所有假设组成的空间中进行搜索的过程,搜索的目标是 找到与训练集匹配的假设,也就是能够将训练集中的瓜判断正确的假设。
假设的表示一旦确定下来,假设空间及其规模大小就确定了。
简单的讲,假设就是所有属性的所有取值情况(不受数据集约束)。
| 编号 | 色泽 | 根蒂 | 敲声 | 好瓜 |
|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 2 | 乌黑 | 蜷缩 | 浊响 | 是 |
| 3 | 青绿 | 硬挺 | 清脆 | 否 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 否 |
与数据集匹配的假设就是
色泽 = *; 根蒂 = 蜷缩; 敲声 = 浊响
也就是好瓜就是,根蒂蜷缩、敲声浊响,什么色泽都行的瓜。
这个能够判断所有数据集的“假设集合”已经非常接近版本空间,版本空间与这个“假设集合”的区别主要是因为。版本空间是将所有假设全部列出来后,然后用数据集一个一个去进行搜索,然后将删除与正例不一致的假设。这里主要的问题就是,对于一些属性它无法进行判断,因为数据集没有覆盖完整。
在做题的时候,也只有尽可能的往上面再想一层,看看它那个属性的上一层就算取任意值也算正例。
版本空间例题1
| 编号 | 姓名 | 年收入 | 性别 | 职业 | 好顾客 |
|---|---|---|---|---|---|
| 1 | 张三 | 高 | 男 | 程序员 | 是 |
| 2 | 李四 | 高 | 男 | 企业家 | 是 |
| 3 | 王五 | 中 | 男 | 公务员 | 否 |
| 4 | 周六 | 低 | 女 | 学生 | 否 |
| 5 | 钱七 | 中 | 女 | 教师 | 否 |
给出上表所对应的版本空间,用符号 * 表示取任何值都可以。
答案
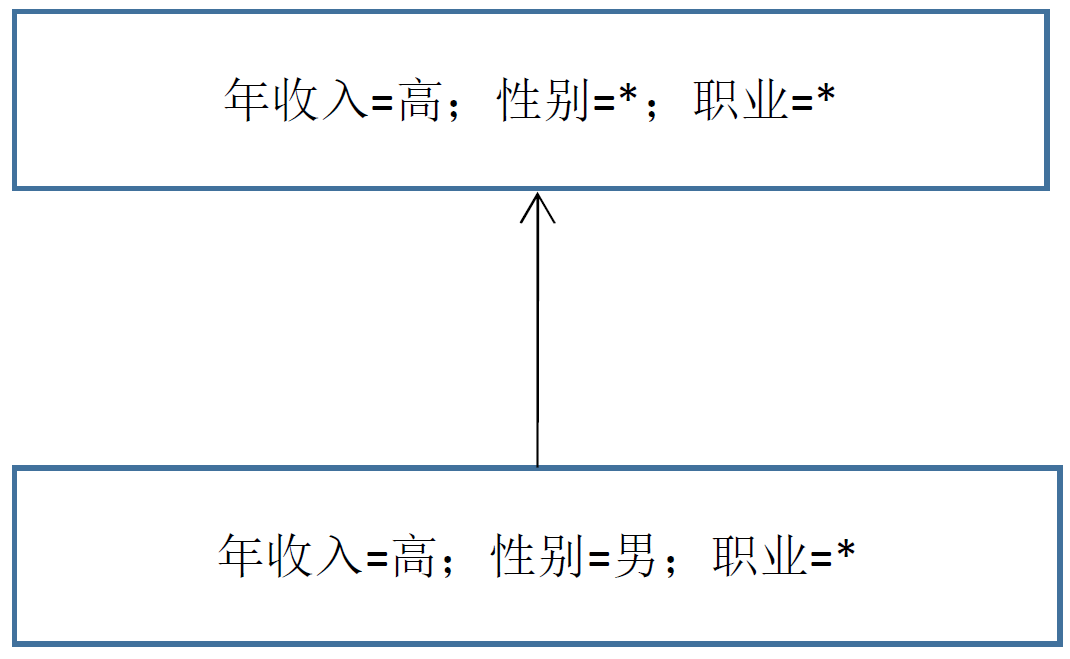
版本空间例题2
| 编号 | 色泽 | 根蒂 | 敲声 | 好瓜 |
|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 2 | 乌黑 | 蜷缩 | 浊响 | 是 |
| 3 | 青绿 | 硬挺 | 清脆 | 否 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 否 |
该数据集的版本空间是?
答案

归纳偏好
通过上面的 版本空间例题2 可以了解到,我们通过学习获得了 3 个与训练集一致的假设(版本空间里面有 3 种不同的假设)。但是有一个问题,就是它在面临新样本的时候,可能会输出不同的结果。
比如这里有个新瓜
色泽 = 青绿; 根茎 = 蜷缩; 敲声 = 沉闷
如果使用 B 条件(点开上面的答案)判断,那么它会把这个新瓜判断为好瓜。
但是如果使用 C 条件判断,那么它会把这个新瓜判断为坏瓜。
如果在我们使用机器学习算法的时候,遇到这种样本它每次都随机挑选一个条件进行判断,进而导致每次预测的时候结果时而好又时而坏,这样的学习结果显然是没有意义的。
所以我们需要让机器学习算法在学习的过程中,要对于某种类型的假设有偏好。我们就称其为归纳偏好,或简称为偏好。
比如它的偏好如果是“尽可能特殊”的模型,那么它就会选择版本空间右上角那一个,因为这个模型确定了 3 种属性分别都是一个具体的取值。
又比如它的偏好是“尽可能一般”的模型,并且由于某种原因它更相信根蒂,那么它就会选择版本空间左上角那一个。因为这个模型更多的使用了 * 来确认取值,同时它指定了根茎是蜷缩。
奥卡姆剃刀
奥卡姆剃刀就是一种用来,评判哪一种“偏好”更好的原则。也即是若有多个假设与观察一致,则选择最简单的那个。
可以总结为,简单的就是最好的
这里的每个训练样本是图中的一个点(x,y),要学习一个与训练集一致的模型,相当于找到一条穿过所有训练样本的曲线。
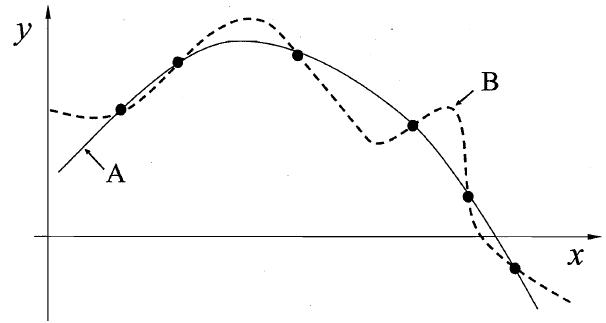
在这里我们就列举出了两条曲线,其中 A 是较为平滑的一条它的方程式是 $y=-x^2+6x+1$ ,而 B 曲线是要复杂很多。
假设我们认为“更平滑”意味着“更简单”,所以在上面的图中我们会自然的偏好于选择更平滑的曲线 A。
但是奥卡姆剃刀并不是唯一可行的原则,因为在很多问题中,我们并不能找到哪一种假设更简单。同时也有一个问题,万一所有的样本都比较刁钻,他们都正好和 B 完全重合了呢?这个也正是下面这个定理要说明的。
没有免费的午餐
首先你不要被这个定理的名字所迷惑,可以先把这个命名放在另一边,看看定理的内容。
简单的描述这个定理就是,没有任何一个机器学习算法适合所有情况。
这个定理也很符合我们的直觉,就和上面奥卡姆剃刀举例的那两个曲线一样。A 曲线所代表的的机器学习算法,比 B 曲线的机器学习算法要牛逼些吗?并不是,因为 没有免费的午餐 定理证明了他们两种及其学习算法的正确率是完全一致的。
说人话就是,对于所有机器学习问题,任何一种算法的期望性能都是相等的。
但是也不要因为这个定理就觉得机器学习没意思了,因为这个定理有一个前提。也就是,所有问题出现的机会相同、或所有问题同等重要。但是在实际情况中,我们的很多问题都不是这样的,你只需要关注自己需要解决的问题就行了。
比如在学校里面有个电瓶车代步是一个很方便的选择,但是你如果要去外地又或是去国外,那么你可能坐飞机会更好一些。但是你就是想在学校里面找个代步工具,那么买飞机的事情你就不需要关心了。
返回到这个定理上面来,其实它想说的和丢了芝麻捡西瓜一样,也就是有得必有失。某一个机器学习算法在某一个领域非常好用,但是换到另一个地方却完全不好使了。
也就是说,当天上突然掉馅饼的时候你现在吃到了,但是你之后就会遇到很倒霉的事情。这么说应该就能理解没有免费的午餐是什么意思了。
经验误差与过拟合
如果在 m 个样本中有 α 个样本分类错误,则错误率 $E=\frac{a}{m}$
精度:$1-\frac{a}{m}$,也即是精度=1-错误率。
误差:学习器的实际预测输出与样本的真实输出之间的差异。(对单个样本的学习)
训练误差/经验误差:学习器在训练集上的误差。(整个数据集)
泛化误差:在新样本上的误差。
我们希望得到泛化误差小的学习器。然而,我们事先并不知道新样本是什么样,实际能做的是努力使经验误差最小化。
过拟合:当学习器把训练样本学得”太好”了的时候,很可能巳经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这就是过拟合。
过拟合是无法彻底避免的,我们所能做的只是“缓解”,或者说减小其风险。
欠拟合:这是指对训练样本的一般性质尚未学好。
欠拟合比较容易克服,例如在决策树学习中扩展分支、在神经网络学习中增加训练轮数等。
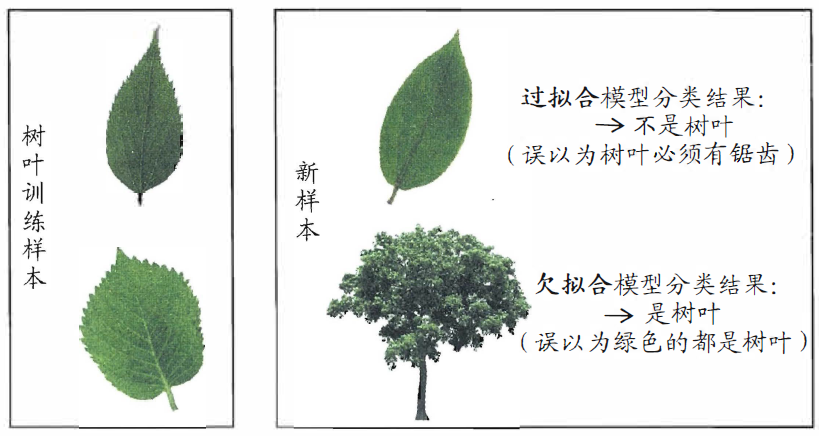
留出法
这是评估方法的一种,使用测试集来测试学习器对新样本的判别能力,在测试集上面的测试误差就可以作为泛化误差的近似。同时要使测试集应尽可能的与训练集互斥,也就是测试样本尽量不在训练集中出现、未在训练过程中使用过。
假定数据集包含 1000 个样本,将其划分为一个 S 集合包含 700 个样本,另一个 T 集合包含 300 个样本。用 S 集合进行训练后,在使用 T 集合进行测试。通过统计测试结果的正确率,就能知道精度和错误率了。这个方法就是留出法。
划分的时候一般都是 训练集样本数 > 测试集样本数。 $\frac{2}{3} \text{~} \frac{4}{5}$ 的样本用于训练,剩下的测试。
划分训练集和测试集时,要尽可能保持数据分布的一致性。
比如整个数据集有 500 个正例、500 个反例,则划分时 S 应包含 350 个正例、350 个反例,而 T 则包含150 个正例和 150 个反例。这个也叫分层采样,若 S、T 中样本类别比例差别很大,则误差估计将由于训练/测试数据分布的差异而产生偏差。
还有一个问题,如果初始数据集里面样本的顺序很极端,前 500 个全是正例,后 500 个全是反例。直接划分的话就不准确,所以单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
交叉检验法
先将数据集划分为 k 个大小相似的互斥子集,也就是每一个子集都尽可能保持数据分布的一致性(都不重复)。
然后每次都只取其中的最后一个为测试集,前面几个都用来做训练集。
最终返回的是这 k 个测试结果的均值。显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于 k 的取值,为强调这一点,通常把交叉验证法称 k 折交叉验证。k 最常用的取值为 10,此时称为 10 折交叉验证。
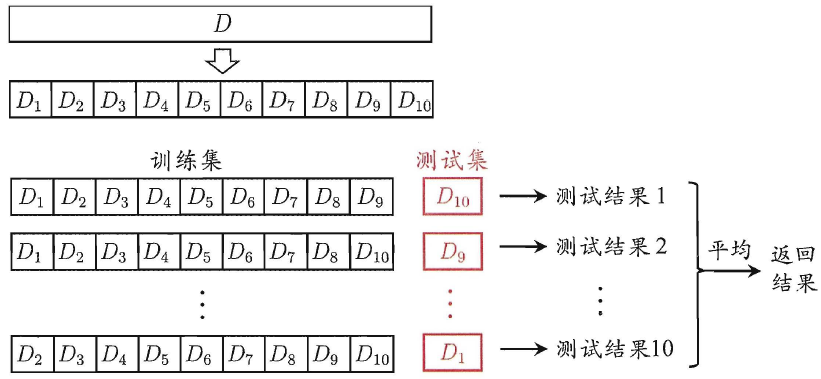
假定数据集 D 中包含 m 个样本,若令 k=m , 则得到了交叉验证法的一个特列:留一法。也就是每一个子集只包含一个样本。测试集就取整个数据集的最后一个。
留一法的评估结果往往被认为比较准确,但是他也有缺陷,留一法在数据集比较大时训练模型的计算开销可能是难以忍受的。另外,留一法的估计结果也未必永远比其他评估方法准确,“没有免费的午餐”定理对实验评估方法同样适用。
自助法
给定包含 m 个样本的数据集 D , 我们对它进行采样产生数据集 D’:
每次随机从 D 中挑选一个样本, 将其拷贝放入 D’ 然后再将该样本放回初始数据集 D 中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行 m 次后,我们就得到了包含 m 个样本的数据集 D’,这就是自助采样的结果。
我们还可以估计样本在 m 次采样中始终不被采到的概率
$$
\begin{aligned}
P&=\lim\limits_{m→∞}(1-\frac{1}{m})^m \
&=\frac{1}{e} \
&≈0.368
\end{aligned}
$$
自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处.然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。因此,在初始数据量足够时,留出法和交叉验证法更常用一些。
性能度量
对模型泛化能力的评价标准就是性能度量。
因为对于不同的模型,使用不同的性能度量方法会导致不同的评判结果。这意味着模型的“好坏”是相对的,一个好的模型不只是它的算法好坏,还取决于它的任务需求。
比如回归任务最常用的性能度量是“均方误差”(mean squared error)
$$
E(f;D) = \frac{1}{m}\sum_{i = 1}^m (f(x_i) - y_i)^2
$$
$E$:数学期望,也就是均值。是一种概率论概念,样本出现的情况结合出现的概率,是一种加权平均。(最后一步都是求平均值,这个公式其实和平均值有点类似)
$f$:代指我们训练的模型。
$D$:数据集。
$m$:样本的总数量。
$i$:当前样本的下标。
$x_i$:第 i 个样本的预测结果的标签(好瓜/坏瓜)。
$y_i$:第 i 个样本的标签真实值。
$\displaystyle\sum_{i=1}^m(x_i)$:通过下标将所有 x 相加起来。和 for 循环差不多。
1 | int sum = 0; |
简单来说,就是把所有预测值和真实值相减,然后在求他们的平方之和。最后再求个平均值。
错误率与精度
错误率和精度是分类任务(预测的结果是布尔值的任务)中最常用的两种性能度量。
他们既适用于二分类任务,也适用于多分类任务。
错误率
对样例集 $D$,分类错误率定义为
$$
E(f;D) = \frac{1}{m}\sum_{i = 1}^m \text{Ⅱ}(f(x_i) \ne y_i)
$$
$E(f;D)$:对模型 $f$ 和数据集 $D$ 的数学期望。
$m$:样本的总数量。
$i$:当前样本的下标。
$x_i$:第 i 个样本的预测结果的标签(好瓜/坏瓜)。
$y_i$:第 i 个样本的标签真实值。
$Ⅱ$:相当于定义的一个函数,和 $f(x)$ 概念类似,只是它这个符号比较迷惑。
$$
Ⅱ(f({x_i}) \ne {y_i}) = \begin{cases}
1 ,&\text{if }f(x_i) \ne y_i \
0 ,&\text{if }f(x_i) = y_i
\end{cases}
$$
也就是:
- 如果预测值和实际值相等,那么这个函数输出 0。
- 如果预测值和实际值有偏差,那么这个函数输出 1。
最后又把他们输出的所有值全部加起来,再求个平均值。
精度
精度也就是正确率,上面求出来了错误率,那么直接用 1 减去它就行了。
$$ acc(f;D) = 1-E(f;D) $$
$acc(f;D)$:acc 是 Accuracy 的缩写,意思是 准确/精确 率。
$E(f;D)$:就是上面的错误率。
当然了你也可以通过改写上面的 $Ⅱ$ 函数,直接计算精度。
$$ E(f;D) = \frac{1}{m}\sum\limits_{i = 1}^m Ⅱ(f({x_i}) \color{blue}= \color{black}{y_i}) $$
将 $Ⅱ$ 函数改成:
- 如果预测值和实际值相等,那么这个函数输出 1。
- 如果预测值和实际值有偏差,那么这个函数输出 0。
$$
Ⅱ(f({x_i}) \color{blue}=\color{black} {y_i}) = \begin{cases}
1 ,&\text{if }f(x_i) \color{blue}=\color{black} y_i \
0 ,&\text{if }f(x_i) \color{blue}\ne\color{black} y_i
\end{cases}
$$
注意这里的 $=$ 和 $\ne$ 与上面错误率的公式有差别。
通过改写后,我们就相当于通过 $Ⅱ$ 直接求出了正确样本的总个数,再通过最外面的 $\frac{1}{m}$ 就直接可以求出正确率的百分比了。
查准率与查全率
查准率(Precision):判定是对的样例中,到底有多少真是对的。
查全率(Recall):所有对的样例,你找出了多少,或者说你判断对了多少。
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例)true positive | FN(假反例)false negative |
| 反例 | FP(假正例)false positive | TN(真反例)true negative |
这个就叫混淆矩阵
查准率 P 与 查全率 R 分别定义为
$$ p=\frac{TP}{TP+FP} $$
$$ R=\frac{TP}{TP+FN} $$
查准率和查全率是一对矛盾的变量。一般来说,其中一个高另一个就会低。
比如,要尽可能将好瓜选出来,那么就增加选瓜的数量,如果把所有瓜都选上了,好瓜肯定也都选上了。但是这样的话查准率就会很低。反之亦然。
F1 度量
F1 度量是用于找到一个查全率和查准率的平衡点算法。
$$
F1 = \frac{2×P×R}{P+R} = \frac{2×TP}{样例总数+TP-TN}
$$
F1 度量还可以通过调整参数,让他向查全率偏重,或者是向查准率偏重。
$$
F_β = \frac{(1+β^2)×P×R}{(β^2×P)+R}
$$
$$
F_β = \begin{cases}
偏重查全率 &β>1\
标准 F1 &β=1\
偏重查准率 &β<1
\end{cases}
$$
宏/微F1
很多时候我们有多个二分类混淆矩阵(忘了混淆矩阵是什么的去这里看看),然后我们有一个方法可以在 n 个二分类混淆矩阵上综合考察查准率和查全率。
- 宏:先计算查准率和查全率再求平均值。
- 微:先计算 TP、FP、TN、FN 的平均值再求查准率和查全率。
宏
你要先回想以前之前的,查准率(Precision)和查全率(Recall)。
$$ P=\frac{TP}{TP+FP} $$
$$ R=\frac{TP}{TP+FN} $$
宏查准率与宏查全率就是把他们求了个平均值。
宏(macro)查准率:
$$
macro-P = \frac{1}{n}\sum_{i=1}^nP_i
$$
宏查全率:
$$
macro-R = \frac{1}{n}\sum_{i=1}^nR_i
$$
可以理解为,先把每一个混淆矩阵的 P 和 R 都求出来,然后再把他们求个平均值就行了。
后面的宏 F1 也就比较好理解,还是回想之前计算 F1 的公式。
$$
F1 = \frac{2×P×R}{P+R}
$$
令上面式子的 $P=macro-P$ 同时令 $R=macro-R$ 那么就可以得到下面的式子了
$$
macro-F1 = \frac{2×macro-P×macro-R}{macro-P+macro-R}
$$
微
介绍完了宏,再来介绍一下微(micro)。还是放一下这个混淆矩阵.
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例)true positive | FN(假反例)false negative |
| 反例 | FP(假正例)false positive | TN(真反例)true negative |
当有多个混淆矩阵的时候,你也会有很多个 TP、FN、FP、TN。那么你可以先分别计算所有混淆矩阵的 TP、FN、FP、TN 的平均值。我们将求过平均值后的数上面画一个横线,那么就有。
$TP$ 的平均值为 $\overline{TP}$
$FN$ 的平均值为 $\overline{FN}$
$FP$ 的平均值为 $\overline{FP}$
$TN$ 的平均值为 $\overline{TN}$
有了这四个参数,我们再回头看看之前的查准率和查全率公式:
$$ P=\frac{TP}{TP+FP} $$
$$ R=\frac{TP}{TP+FN} $$
把里面的变量都用计算平均值过后的替换一下,就可以计算微(micro)查准率:
$$
micro-P = \frac{\overline{TP}}{\overline{TP}+\overline{FP}}
$$
微查全率也很简单啦:
$$
micro-R = \frac{\overline{TP}}{\overline{TP}+\overline{FN}}
$$
后面的微 F1 也是把每一位的都替换一下就行了:
$$
micro-F1 = \frac{2×micro-P×micro-R}{micro-P×micro-R}
$$
P-R ROC AUC
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例)true positive | FN(假反例)false negative |
| 反例 | FP(假正例)false positive | TN(真反例)true negative |
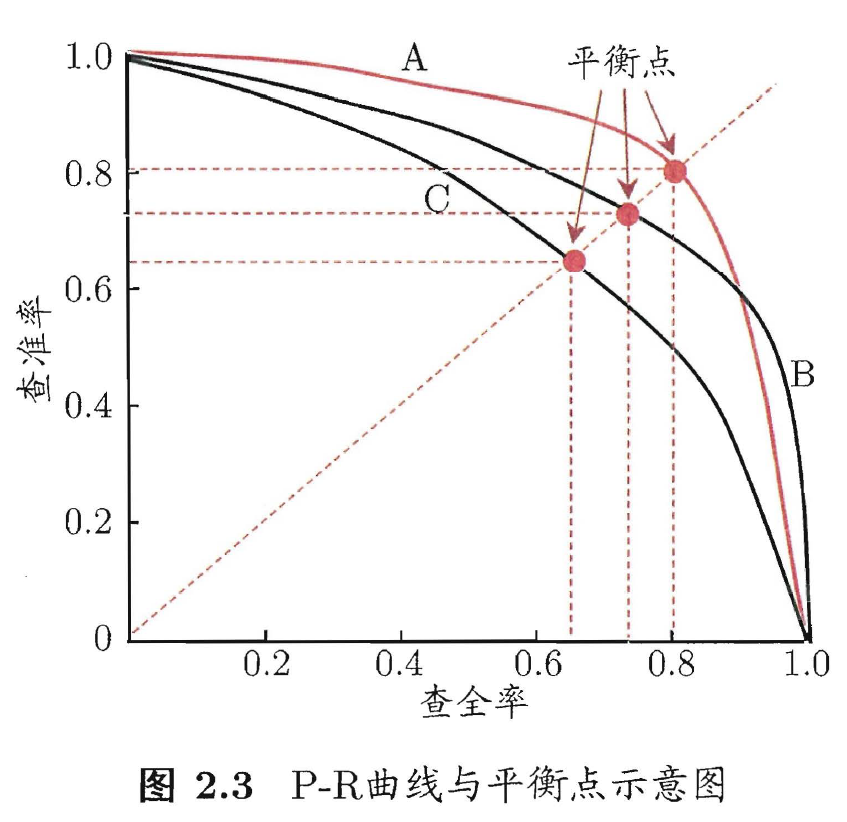
P-R
P-R 曲线横坐标是查全率:
$$ R=\frac{TP}{TP+FN} $$
纵坐标是查准率:
$$ P=\frac{TP}{TP+FP} $$
ROC
横坐标的两个参数,都是混淆矩阵的第二行,这个分子的 FP 是我们不想要的。
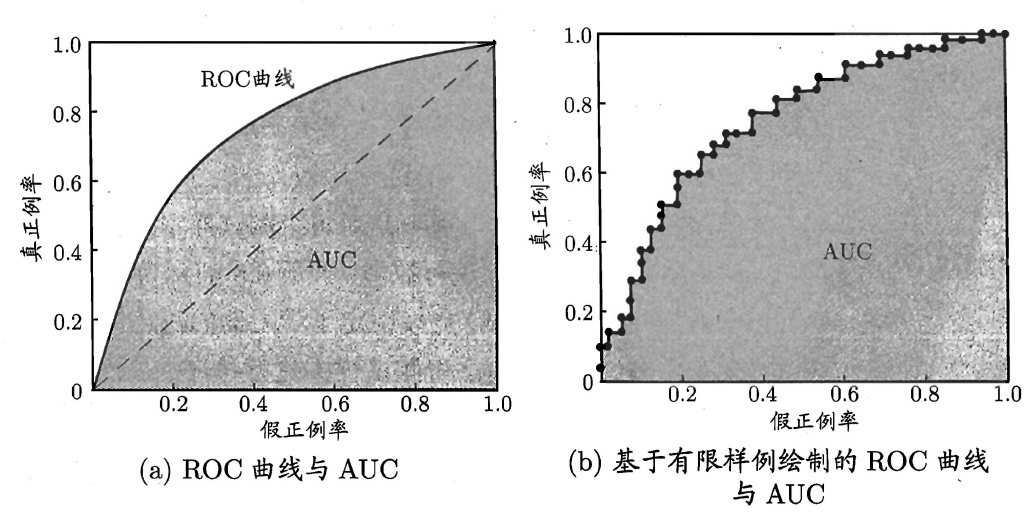
ROC 曲线的横坐标是假正例率(Flase Positive Rate):
$$ FPR=\frac{FP}{FP+TN} $$
纵坐标的两个参数,都是混淆矩阵的第一行,这个分子的 TP 是我们想要的。
纵坐标是真正例率(True Positive Rate),这个公式和 $R$ 是一摸一样的。
$$ TPR=\frac{TP}{TP+FN} $$
我们最想要的就是横坐标很小,但是纵坐标很大的模型。
左边这个图在绘制的时候,是人工美化让他变光滑了的。
但是右边这个图才是实际情况下的图,因为样本数量是有限的,两个点之间的距离也都是直线,所以就会有很多锯齿。
左边那个图,中间的虚线不用去理解它。同时你也要注意,左图的 AUC 指的是阴影部分,和那个虚线没有任何关系。
AUC
AUC(Area Under ROC Curve)指的 ROC 曲线下面的面积,而这个面积越大,这个模型就越好。
虽然 AUC 这个概念只是说的 ROC 但是 P-R 曲线也是曲线下面的面积越大越好。
术语中英对照
| 中文 | 英文 | 备注 |
|---|---|---|
| 数据集 | data set | |
| 实例 | instance | 每一条记录 |
| 样本 | sample | 又名实例 |
| 属性 | attribute | 描述样本的什么方面 |
| 特征 | feature | 又名属性 |
| 属性样本 | attribute space | |
| 特征向量 | feature vector | 在空间中确认一个点 |
| 维数 | dimensionality | 样本有多少属性 |
| 学习 | learning | |
| 训练数据 | training data | |
| 训练样本 | training sample | |
| 训练集 | training set | |
| 假设 | hypothesis | 关于数据的某种规律 |
| 标记 | label | 真假 |
| 样例 | example | 有标记的样本 |
| 标记空间 | label space | 所有标记的集合 |
| 分类 | classification | 预测的布尔值 |
| 回归 | regression | 预测的连续值 |
| 二分类 | binary classification | 预测类别只有两个 |
| 多分类 | multi-class classification | 预测类别有两个以上 |
| 测试 | testing | |
| 测试样本 | testing sample | |
| 聚类 | clustering | 给训练集分组 |
| 簇 | cluster | 每个组就是一个簇 |
| 监督学习 | supervised learning | 有标记 |
| 无监督学习 | unsupervised learning | 无标记 |
| 泛化 | generalization | 学习样本的能力 |
| 归纳 | induction | 从具体事实归纳出规律 |
| 演绎 | deduction | 从基础原理推导出具体情况 |
| 特化 | specialization | 描述演绎的过程 |
| 归纳学习 | inductive learning | 从具体事实归结出一般性规律 |
| 概念 | concept | 对样本的描述 |