Hadoop 添加和删除节点
Hadoop 集群的添加和删除节点比较容易,这里也就做个记录。
环境介绍
目前我使用的虚拟机搭建,共有 1 个 NameNode 和 另外 2 个 DataNode
| HostName | Function | ip |
| — | — | — | — |
| master | NameNode/DataNode | 192.168.66.128 |
| slave1 | DataNode | 192.168.66.129 |
| slave2 | DataNode | 192.168.66.130 |
hdfs-site.xml 中的 dfs.replication 使用的默认值 3
关键配置
因为我之前在部署环境的时候没有设置 dfs.hosts 和 dfs.hosts.exclude 。先简单介绍一下。
dfs.hosts 是在 hdfs-site.xml 中的一项配置,它定义了允许连接到 NameNode 的主机列表。在默认情况下(不配置该项)就会允许所有主机。
dfs.hosts.exclude 是在 hdfs-site.xml 中的一项配置,它的功能正好与 dfs.hosts 相反,它是用于定义不允许连接到 NameNode 的主机列表。在默认情况下(不配置该项)就不会排除任何主机。
类似的,资源管理器配置文件 yarn-site.xml 中也拥有与 HDFS 这两项功能相似的配置,分别为 yarn.resourcemanager.nodes.include-path 和 yarn.resourcemanager.nodes.exclude-path
一般情况下,我们会将 yarn.resourcemanager.nodes.include-path 和 dfs.hosts 指向同一个文件,将 yarn.resourcemanager.nodes.exclude-path 和 dfs.hosts.exclude 指向同一文件。但是他们在特殊情况下,具体的实现会细微的差别,后面再提。
准备工作
首先为了操作方便我们先创建好 include 和 exclude 文件,并往 include 中写入已存在的集群信息并测试一下是否运行正常
1 | vi $HADOOP_HOME/etc/hadoop/include |
exclude 先不写入信息,准备好就行了
1 | touch $HADOOP_HOME/etc/hadoop/exclude |
停止服务修改配置文件
1 | stop-all.sh |
写入以下信息
1 | <configuration> |
1 | vi $HADOOP_HOME/etc/hadoop/yarn-site.xml |
添加以下信息
1 | <property> |
启动服务
1 | start-dfs.sh |
用 hdfs dfs -ls / 和 get/put 之类的试试 HDFS 工作正常不,然后也可以用 hive 的 select count(*) 之类的语句一下 MapReduce 工作正常不,如果正常的话就可以走下一步了。
删除节点
判断一个节点能否连接到资源管理器非常简单。仅当节点出现在 include 文件且不出现在 exclude 文件中时,才能够连接到资源管理器。注意,如果未指定 include 文件或为空的话,则意味着所有节点都可以连接到资源管理器。
对于 HDFS 来说,include 和 exclude 文件稍有不同,如果一个 DataNode 在 include 文件中出现同时也在 exlude 中那么说明该节点即将被删除添加。下表总结了 DataNode 的不同组合方式。
| 是否在 include 中 | 是否在 exclude 中 | 状态 |
|---|---|---|
| 否 | 否 | 无法连接 |
| 否 | 是 | 无法连接 |
| 是 | 否 | 可连接 |
| 是 | 是 | 可连接,将被删除 |
需要注意的是
dfs.hosts和yarn.resourcemanager.nodes.include-path属性指定的文件(include和exclude)不同于slaves文件,前者供NameNode和资源管理器使用,用于决定可以连接那些节点。Hadoop 控制脚本使用slaves文件执行面向整个集群范围的操作,例如重启集群等。Hadoop 守护进程从不使用slaves文件。
进入 exclude 配置,写入即将删除的节点
1 | vi $HADOOP_HOME/etc/hadoop/exclude |
1 | slave2 |
运行以下指令,将节点信息更新至 NameNode 和 资源管理器
1 | hdfs dfsadmin -refreshNodes |
你可以在 WEB 端看到 Datanode 的 Admin State 变化如下 In Service > Decommission In Progress > Decommissioned
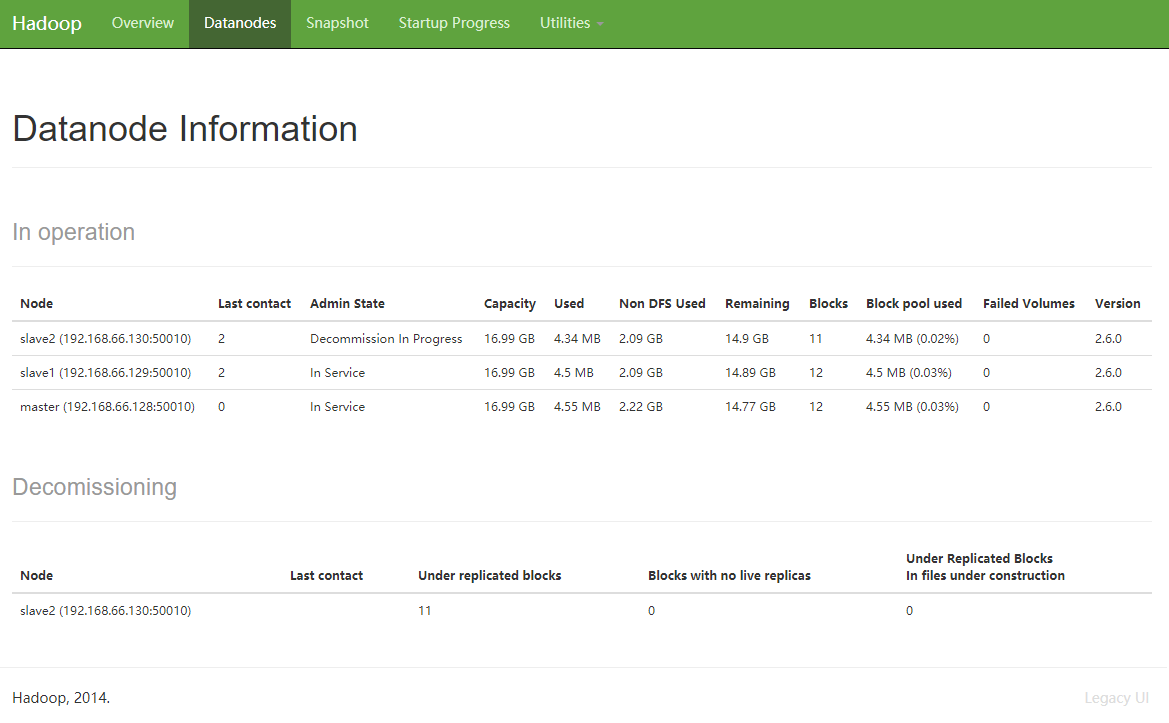
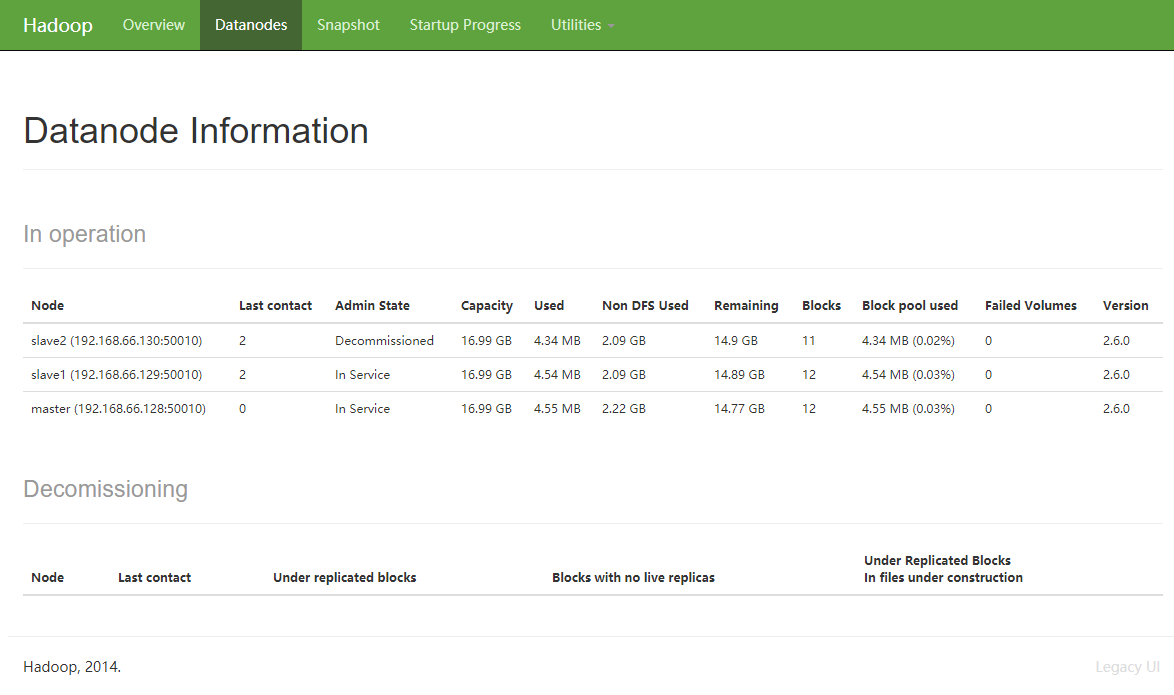
如果在
Decommission In Progress卡了很久,可能是你没有吧dfs.replication调低。我之前遇到了这个问题。
同时我在删除了1个节点后 HDFS 会疯狂报错,一直找不到解决方案。但是它也不影响 HDFS 的正常运行就直接无视了 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 1 to reach 3 (unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) All required storage types are unavailable: unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
资源管理器状态如下

接下来你就可以将该节点从 include 文件中完全移除了
1 | vi $HADOOP_HOME/etc/hadoop/include |
更新一下节点信息
1 | hdfs dfsadmin -refreshNodes |
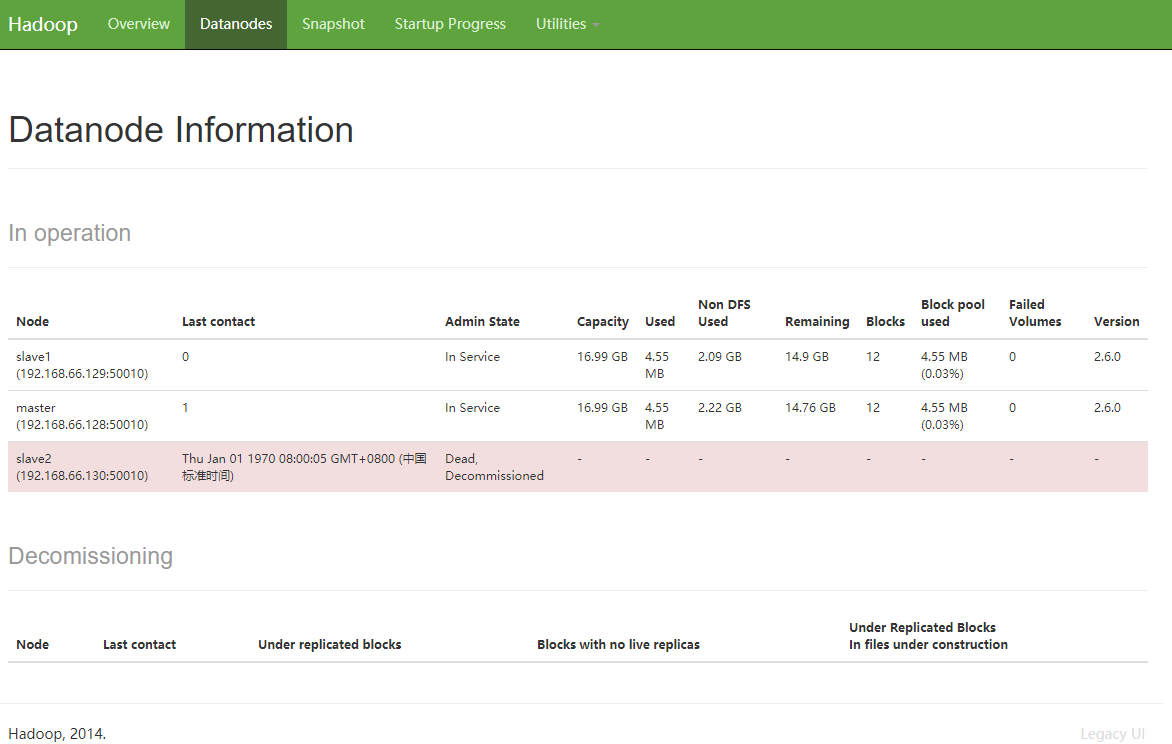
如图,节点已经被完全删除了
添加节点
添加一个刚刚被删除的节点,会让它感到懵逼。所以这里我们先重启一下。
1 | stop-yarn.sh |
直接将节点信息添加进 include ,同时把它从 exclude 中删除
1 | vi $HADOOP_HOME/etc/hadoop/include |
1 | vi $HADOOP_HOME/etc/hadoop/exclude |
更新一下节点信息
1 | hdfs dfsadmin -refreshNodes |
添加节点成功
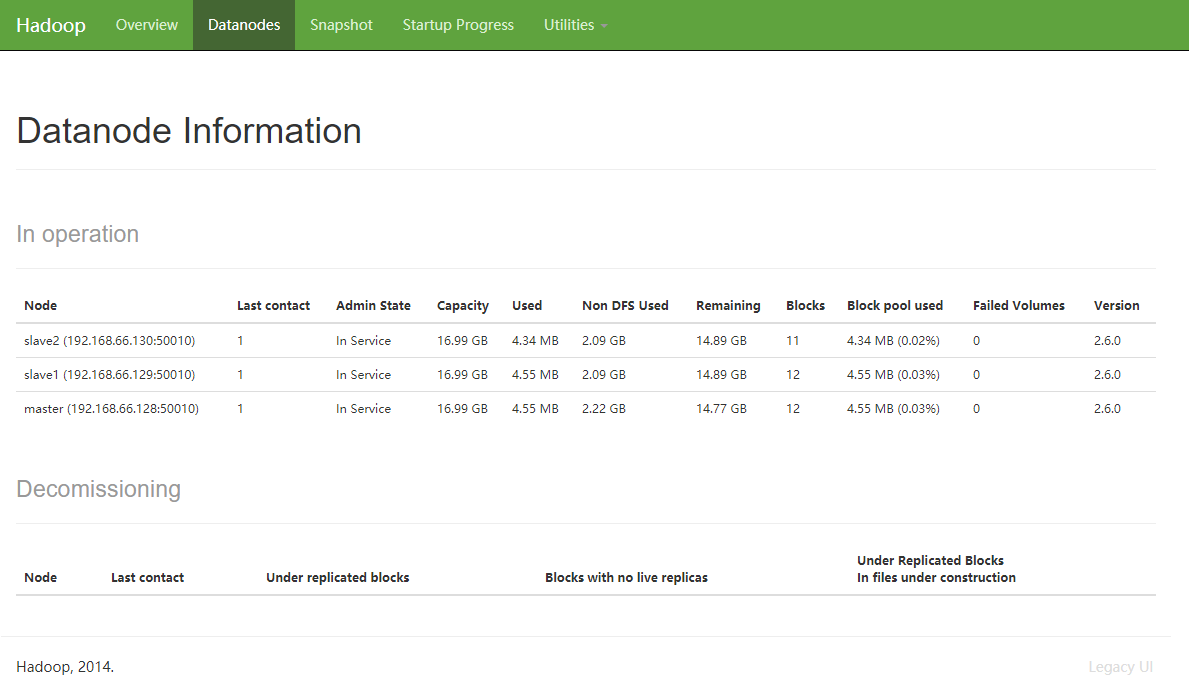

其他 大数据系列文章 请看 这里
参考
Hadoop: The Definitive Guide@Tom White